Wie entsteht eigentlich die Idee zu einer Master-Arbeit? Wie finden Professor und Student zusammen? Ist es von der Idee bis zur Abgabe eine Einbahnstraße, oder werden immer und immer wieder über neue Stolpersteine gestolpert, neue Inspirationen inspiriert, neue ... ? Selbstverständlich sind letztere Punkte der Fall - Ansonsten hätte man offensichtlich nichts dazugelernt! Dieser Blog verdeutlich dies und gibt darüber hinaus Einsichten in unsere Arbeitsweise; was u.A. die anderen Fragen abdeckt.
Ehrlicherweise muss ich gestehen, dass das kein echter Blog ist (auch wenn das eine gute Idee gewesen wäre, wie in wissenschaftliches Arbeiten im 21. Jahrhundert diskutiert). Hier sind unsere niedergeschriebenen Gedankengänge, die nachträglich in diesen Blog umgewandelt wurden. Im Allgemeinen kann ich das Niederschreiben von Gedankengängen jedem nur wärmstens empfehlen. Es hilft die Gedanken zu sortieren und auszupfeilen. Des Weiteren zeigt einem das Niederschreiben brutalst, wo man etwas noch nicht genau verstanden hat; nämlich genau da, wo man beim Schreiben stockt. Dies ist etwas sehr positives, da man so geradezu zum Nachdenken über die Schwierigkeiten gezwungen wird. Auch können andere dann die Gedanken und ggf. Schwierigkeiten lesen, nachvollziehen und beim Arbeiten unterstützen. So werden früh Irrewege abgekürzt, was die Zeit des Niederschreibens mehr als wieder einholt :)
Angefangen hat alles damit, dass mein betreuender Professor Herr Luttenberger Frau Davidis' Kochbuch geschenkt bekommen hat. Er hat dann natürlich angefangen, sich darüber Gedanken zu machen. Diese Gedanken hat er in einem Word-Dokument Tagebuch-ähnlich niedergeschrieben. Diese Einträge bilden quasi den Startschuss und daher fängt dieser Blog mit ihnen an. Das original Word-Dokument kann hier heruntergeladen werden.
In der Vorlesung Web-Technologien hat Herr Luttenberger kurz das Paper vorgestellt, welches die westliche mit der asiatischen Küche vergleicht. Ich konnte mit meinem Koch-Domänen-spezifischen Wissen glänzen, dass Muskatnuß und Muskatblüte zwei unterschiedliche Gewürze sind (s. hier). Nach der Vorlesung hat Herr Luttenberger mich dann angeworben, ob ich nicht Lust hätte als SHK die Reise mit Davidis' Kochbuch zu teilen. Wie hoffentlich an dieser Webseite ersichtlich ist, bin ich mit viel Herzensblut vorangestürmt. Doch diese Webseite ist natürlich viel mehr als ein kurzer 100m Sprint.
Zunächst habe ich mich also als SHK 3 Monate mit dem Kochbuch beschäftigt. Man könnte sagen, ich habe den Blog von Herrn Luttenberger damit übernommen. Ähnlich wie er, habe ich regelmäßig meine Gedankengänge und neuen Erkentnisse Tagebuch-ähnlich niedergeschrieben. Diese Einträge bilden somit den 2. Teil des Blogs. Die originalen Word-Dokumente können hier heruntergeladen werden.
Da viele Erkenntnisse der Form waren Das passt noch nicht wirklich, haben wir an die SHK-Tätigkeit diese Master-Arbeit drangehangen. Mittwochs gibt es bei Herrn Lutternberger immer ein Seminar, in dem einige Studenten ihre neuesten Erkenntise bezüglich ihrer Abschluss-Arbeit vorstellen. Die PDFs meiner Präsentationen bilden den 3. Teil des Blogs. Da ich die Metapher eine Abschluss-Arbeit mit einer abenteuerlichen Reise zu vergleichen sehr schön finde, habe ich jeder Präsentation einen Titel gegeben - so wie jedes Kapitel eines guten Romans einen Titel hat. Vor jedem PDF gönne ich mir daher ein bis zwei Sätze, um die Assoziation mit dem Titel zu erläutern.
Abschließend nach diesem langen Vorwort noch alle Titel meiner Präsentationen - sind diese nicht eine viel versprechende Reise?
- Der Beginn einer Master-Arbeit
- Irrlichter
- Heraus aus dem Sumpf
- Ritter und Fabelwesen
- Das Festmahl zum Schluss (natürlich nach Davidis' Kochbuch zubereitet)
Nun wollen wir aber zuerst mit dem Anfang anfangen...
Norbert Luttenbergers Eintrag Nr. 1
Anlässlich des diesjährigen gemeinsamen Abendessens der AG ComSys (ganz hervorragend von unserem Masterstudenten Dennis Sen und seiner Liebsten zubereitet) hat mein Mitarbeiter Jesper Zedlitz mir als dem Gastgeber ein Buch geschenkt. Wie es bei Jesper üblich ist: nicht irgendein Buch – kein bluttriefender Krimi, kein pistolenschwingender Agententhriller, kein gänsehäutiger Horrorschocker – nein, all das nicht. Sondern ein altes Buch. Genauer gesagt: ein altes Kochbuch. Ein Kochbuch aus dem Antiquariat.
Nun soll man sich ja, wenn Jesper einem etwas schenkt, immer auch etwas dabei denken. Altes Buch: Was könnte das bedeuten? Die Antwort zu finden, schien mir einfach: Herr Luttenberger, dieses Buch wollen wir einscannen, wir finden bestimmt jemanden, der es abtippt, und dann wollen wir es der interessierten Öffentlichkeit in Form einer digitalen Edition zur Verfügung stellen. Alte Dokumente zugänglich zu machen – ja, man kann wirklich sagen, dass das zu Jespers Leidenschaften gehört. Warum ein Kochbuch? Nun, die Antwort auf diese Frage zu finden, schien mir nur wirklich sehr einfach: Herr Luttenberger, beim nächsten Mal möchten Sie vielleicht ein Gericht nach einem Rezept aus diesem Buch kochen – wir kommen gerne!
Ich habe noch am gleichen Abend angefangen, in diesem Kochbuch zu lesen. Ehrlich gesagt: hard stuff! Für uns heutige ist "Rezept" eine Textsorte, die aus mindestens zwei Teilen besteht: der Zutatenliste und der Zubereitungsanleitung. Früher war das anders. Der unten gezeigte Auszug aus Henriette Davidis' "Praktischem Kochbuch für die gewöhnliche und feinere Küche" (das ist der Titel des Buchs, das Jesper mir geschenkt hat) belegt es: Zutatenliste und Zubereitungsanleitung sind in einem Absatz vermischt.

Ich habe mir gedacht: Wenn ich wirklich für das nächste gemeinsame Abendessen ein Gericht nach einem Rezept aus diesem Kochbuch kochen soll, dann muss ich das Originalrezept erst decodieren und in ein Rezept nach heutigen Gestaltungsregeln umschreiben. So wie es da aufgeschrieben ist, kann ich es nicht verwenden – diese "Suppe von jungen Gemüsen" würde mir nicht gelingen.
Am nächsten Tag habe ich eine E-Mail von Jesper bekommen: "Lieber Herr Luttenberger, hier habe ich eine TEI-kodierte Fassung des Kochbuchs (vermutlich eine andere Auflage/Ausgabe) gefunden: http://www.deutschestextarchiv.de/book/show/davidis_kochbuch_1849. Die digitale Edition dieses Kochbuchs, die Jesper mir per Buchgeschenk nahelegen wollte, ist vom Deutschen Textarchiv bei der Berlin-Brandenburgische Akademie der Wissenschaften schon erledigt worden, nämlich in Form einer "TEI-codierten Fassung" (s.u.). Sollte die Anpassung an heutige Gestaltungsregeln schon erledigt sein und bliebe also nur noch das Kochen … ?
Wenn ich die Frage so stelle, dann riechst Du, liebe Leserin, schon die Antwort: Nein – da ist noch was zu tun! Ich hole etwas aus und erläutere zunächst einmal, was "TEI-kodierte Fassung des Kochbuchs" bedeutet.
Zunächst einmal hat das Deutsche Textarchiv das Kochbuch "manuell durch Nicht-Muttersprachler im Double Keying-Verfahren erfass[en lassen]". Zwei Nicht-Muttersprachler haben also unabhängig voneinander den Text abgetippt; die abgetippten Texte wurden miteinander verglichen, und bei Unstimmigkeiten wurde eine Korrektur veranlasst. Das ist aber nur die eine Hälfte der Wahrheit. Beim Abtippen (oder auch danach) wird der zu erfassende Text mit TEI tags angereichert, und das ist es, was uns hier mehr interessiert. Für alles andere verweise ich auf die Seiten des Deutschen Textarchivs.
TEI bedeutet Text Encoding Initiative, und diese Initiative hat Guidelines zur Codierung von Texten vorgelegt, die mittlerweile (d.h. in der fünften Version) insgesamt 1853 Seiten umfassen. Kurz gesagt: Es geht um eine Sammlung von XML tags, mit denen man Texte unterschiedlicher Art auszeichnen kann. Dadurch werden die Texte zu strukturierten Texten, und diese können maschinell verarbeitet werden. Klingt wie die Einleitung zu meiner XML-Vorlesung. Weil das so schön ist, zitiere ich aus der Einleitung zu den Guidelines:
"In particular, [these guidelines] specify a set of markers (or tags) which may be inserted in the electronic representation of the text, in order to mark the text structure and other features of interest. Many, or most, computer programs depend on the presence of such explicit markers for their functionality, since without them a digitized text appears to be nothing but a sequence of undifferentiated bits. The success of the World Wide Web, for example, is partly a consequence of its use of such markup to indicate such features as headings and lists on individual pages, and to indicate links between pages. The process of inserting such explicit markers for implicit textual features is often called ‘markup’, or equivalently within this work ‘encoding’; the term ‘tagging’ is also used informally. We use the term encoding scheme or markup language to denote the complete set of rules associated with the use of markup in a given context; we use the term markup vocabulary for the specific set of markers or named distinctions employed by a given encoding scheme."
Wir schauen uns einfach einmal die getagte "Suppe von jungen Gemüsen" an:

Also, mal ehrlich: Besonders schön sieht das ja nicht aus. Da kann man ja beinahe die Frakturschrift leichter lesen als dieses XML …
Im nächsten Blogpost werden wir versuchen herauszufinden, was da passiert ist.
Norbert Luttenbergers Eintrag Nr. 2
Also, was jetzt kommt, könnte so ähnlich klingen wie ein Crash-Kurs zu den Guidelines der Text Encoding Initiative. Naja, oder zumindest in den Teil der Guidelines, den man schnell und leicht verstehen kann.
Damit klar ist, wovon die Rede ist, füge ich hier noch einmal den schon im letzten Blogpost gezeigten Auszug aus der digitalen Edition des "Praktischen Kochbuchs für die gewöhnliche und feinere Küche" von Henriette Davidis in der vom Deutschen Textarchiv besorgten TEI-codierten Fassung ein. Es geht um ein Rezept für eine "Suppe von jungen Gemüsen".
Das Rezept erscheint als textual division und wird, wie leicht zu erkennen ist, in <div> tags eingeschlossen. In den TEI Guidelines wird zum Thema textual (sub)division ausgeführt:
"For example, a major subdivision of an epic or of the Bible is generally called a ‘book’, that of a report is usually called a ‘part’ or ‘section’, that of a novel a ‘chapter’— unless it is an epistolary novel, in which case it may be called a ‘letter’. Even texts which are not organized as linear prose narratives, or not as narratives at all, will frequently be subdivided in a similar way: a drama into ‘acts’ and ‘scenes’; a reference book into ‘sections’; a diary or day book into ‘entries’; a newspaper into ‘issues’ and ‘sections’, and so forth. Because of this variety, these Guidelines propose that all such textual divisions be regarded as occurrences of the same neutrally named elements, with an attribute type used to categorize elements independently of their hierarchic level."
Eine akzeptable Überlegung. Warum allerdings in unserem Rezeptbuch das in den Guidelines vorgeschlagene Attribut type nicht verwendet wird, erschließt sich mir nicht – zumal in den Guidelines ein Beispiel angeführt wird, in dem eine textual division mit einem Attribut type="recipe" versehen ist (S. 1021). Außerdem ist die Verwendung des Attributs n fragwürdig. Das Attribut n="3" gibt hier eine Hierarchie-Ebene an; das ist allerdings nicht die Nutzung des Attributs n, die von den TEI Guidelines vorgeschlagen wird. Hätte man sich an die Guidelines gehalten, dann hat man nicht das tag <div> verwendet, sondern das tag <div3> oder wie wir später noch sehen werden, das tag <div4>.
Nächster Schritt.
In unserem Beispiel wird ein Rezept in ein <head>- und in zwei <p>-Elemente zerlegt. Kann man so machen. Sehr problematisch ist die Tatsache, dass beim encoding die Nummerierung der Überschrift ("25.") mit in den Text des <head>-Elements übernommen wurde. Will man die Überschriftentexte untersuchen oder das Kochbuch neu zusammenstellen, stört diese Zahlenangabe erheblich. Als Attribut zum <div4>-Element wäre sie dagegen sehr sinnvoll gewesen.
Nächster Schritt.
Im <head>-Element und in den beiden <p>-Elementen fallen sofort die ſ entities auf, die dort zahlreich vertreten sind. Worum geht's? Wikipedia weiß Rat: Es geht um das "lange s". Das ist die in der Frakturschrift verwendete Darstellungsweise für den Buchstaben "s" – ich erspare mir hier weitere Details, die man der interessanten und subtilen Argumentation des Wikipedia-Artikels entnehmen möge.
Aber mal ehrlich gesagt: Warum diese typographische Besonderheit der Frakturschrift sich im encoding unseres Kochbuchs einen so breiten Raum verschafft, das kann ich nicht nachvollziehen. Ich kann mir keinen relevanten Forschungsansatz vorstellen, der es schafft, aus der Tatsache des Auftretens des langen s irgendwelche bedeutenden Erkenntnisse abzuleiten. Das soll nicht heißen, dass man nicht erwähnen soll, dass unser Kochbuch in Frakturschrift geschrieben ist. Aber man muss doch nicht jedes lange s als solches codieren! Gegen eine solche Codierung sprechen gleich mehrere Einwände:
- Die Verwendung des langen s behindert die elektronische Suche im Text erheblich; das Wort "Gemüſe" ist nicht durch Eingabe des Strings "Gemüse" auffindbar.
- In der Frakturschrift unterscheiden sich das lange s und das f optisch nur sehr wenig voneinander. Das erschwert das Lesen der Transkription erheblich. Auch einer der Nicht-Muttersprachler ist beim Transkribieren in diese Falle hineingetappt: Im Rezept 10 ("Farce von Mandeln") wird eine der Zutaten wie folgt bezeichnet: "eine Obertaſſe voll Mandeln fein geftoßen". Mahlzeit!
- Wenn denn trotz aller Einwände glaubt, eine Typographie-orientierte Auszeichnung sei nützlich und notwendig, dann muss man sie konsequent durchführen. Wie verhält es sich z. B. mit dem Trennzeichen? Wir sehen im Scan, dass damals ein Trennzeichen verwendet wurde, dass wir heutigen nicht mehr verwenden, nämlich der Doppelbindestrich. In unserem encoding finden wir einen einfachen Trennstrich (und zusätzlich ein <lb/>-Element ("line break"); mehr dazu s.u.), wo im Original ein Wort getrennt wird. Und: Wie verhält es sich mit Ligaturen? Im Original wird die "gehackte Petersilie" nicht mit ck geschrieben, sondern mit einer Ligatur œ.
Ich vermute, dass die Vorgehensweise, einen Scan "manuell durch Nicht-Muttersprachler" transkribieren zu lassen, zu diesem Problem geführt hat. Der Nicht-Muttersprachler kann nur schwer entscheiden, ob im Deutschen das gewöhnliche ("runde") s eine vom langen s verschiedene Bedeutung hat. Der transkribierende Nicht-Muttersprachler wird sich also gesagt haben: Lieber das lange s codieren, als ein Problem kriegen.
Zum Glück kann man das lange s schnell global durch das übliche runde s ersetzen. Ein Problem gelöst.
Nächster Schritt.
Im codierten Text werden, wie schon gesagt, alle Zeilenbrüche durch ein <lb/>-Element markiert. Auch hier frage ich mich: Warum? Gibt es einen relevanten Forschungsansatz, der aus der Tatsache, dass zwischen "so viel" und "Bouillon" ein Zeilenbruch erfolgt, eine Erkenntnis oder wohlmöglich sogar: eine tiefschürfende Erkenntnis abzuleiten in der Lage ist? Es handelt sich hier doch nicht um Gedicht – da könnten Zeilenbrüche und Silbentrennungen sinntragend sein. In einem Kochbuch werden sie schlicht und ergreifend durch die beschränkte Papierbreite erzwungen.
Zum Glück kann man das<lb/>-Element schnell global durch ein Leerzeichen ersetzen.
Viel schwieriger wird es, wenn ein Zeilenbruch zusammen mit einer Silbentrennung passiert. Silbentrennungen werden im vorliegenden encoding durch eine Folge von drei Zeichen codiert: [hyphen]<lb/>[space]. Man könnte denken, man könnte diese Zeichenfolge ohne Schaden komplett entfernen, und alles wäre gut. Aus " Por-<lb/> tulac" würde "Portulac" werden. Leider ist die Sache nicht so einfach. Man stelle sich vor, die Wortfolge "Blumen- oder Spitzkohl" würde durch einen Zeilenbruch wie folgt in zwei Teile geteilt: "Blumen[hyphen]<lb/>[space]oder Spitzkohl". Das komplette Entfernen der Zeichenkette [hyphen]<lb/>[space] würde hier zu einem fehlerhaften Ergebnis führen. In unserer üblichen Schreibung wird leider nicht zwischen einem Trennstrich und einem Bindestrich unterschieden …
Die Lösung: Handarbeit!
(In den "Edition-specific TEI encoding guidelines Nachwuchsgruppe Berliner Intellektuelle 1800 – 1830" wird gezeigt, wie man Zeilenbrüche korrekt codieren könnte. Aber wie gesagt: Bei einem Kochbuch ist die Codierung von Zeilenbrüchen bestimmt als überflüssig zu betrachten.)
Ich zeige jetzt einmal eine erste Version eines text encoding, wie ich es mir vorgestellt hätte.

Was wir jetzt sehen, ist ein Markup, das der maschinellen Verarbeitung die text structure zu erkennen gibt. Zugunsten der Strukturerkennung wird von typographischen Details abstrahiert. Ich habe das <div> tag noch nicht durch ein <div3> tag ersetzt, das anzeigen würde, dass es sich hier um Textelement der dritten Hierarchiestufe handelt. Auch hier erwarten uns noch Schwierigkeiten!
Immer noch bin ich weit von einer Textcodierung entfernt, die es mir erlauben würde, aus dem vorliegenden Buch die Rezepte in einer Form zu extrahieren, wie ich sie gerne haben möchte, um danach ein Gericht für meine AG kochen zu können.
Im nächsten Blogpost geht es weiter.
Norbert Luttenbergers Eintrag Nr. 3
Jetzt habe ich Dich, liebe Leserin, schon über zwei lange Blogposts mit der digitalen Edition des "Praktischen Kochbuchs für die gewöhnliche und feinere Küche" von Henriette Davidis geplagt – aber noch immer bin ich noch nicht da angekommen, wohin ich eigentlich will: Ich will aus diesem Kochbuch die Rezepte extrahieren, und ich will aus den Rezepten die Zutaten extrahieren, und aus den extrahierten Zutaten will ich eine Zutatenliste bauen. Und dann will ich endlich kochen!!!
Leider werden wir auch heute unser Ziel noch nicht erreichen. Aber wir werden wieder einen Schritt weiterkommen: Wir werden es schaffen, aus dem ganzen großen Kochbuch alle Rezepte zu extrahieren.
Wo ist das Problem?
Wie wir ja festgestellt hatten, sind in der digitalen Edition des Deutschen Textarchivs die Rezepte als solche nicht gekennzeichnet; es gibt weder ein XML-Element <recipe>, in das Rezepte eingeschlossen worden wären, noch gibt es ein Attribut type="recipe", das ein <div>-Element näher spezifizieren würde.
Wir überlegen uns, dass ein Kochbuch ein strukturiertes Gebilde ist, das – wie jedes Buch – einen Vorspann, einen Hauptteil und einen Abspann hat. Wir erwarten die Rezepte im Hauptteil. Der Hauptteil zerfällt in eine Folge von Kapiteln ("Fleischgerichte", "Fischgerichte", "Suppen", "Süßspeisen" usw.), und in diesen Kapiteln erwarten wir die Rezepte. Wir wissen schon vorab, dass wir einige dieser Kapitel ausblenden müssen, da sie allgemeine Hinweise zum Einkauf, zur Zubereitung und zur Lagerung von Zutaten enthalten. Aber das ist im Moment noch nicht so wichtig.
Wir stellen uns nun als kundige IxEmEller einen XPath-Ausdruck vor, der alle Rezepte einsammelt. Dieser XPath-Ausdruck muss zunächst in den Hauptteil des Kochbuchs marschieren. Zum Glück ist das bei einer TEI-Codierung einfach: Dort wird der Vorspann mit dem tag <front>, der Hauptteil mit dem tag <body> und der Abspann mit dem tag <back> ausgezeichnet. Alle Kapitel des Hauptteils sind in <div>-Elemente eingeschlossen. Wo also ist das Problem? Da wir wissen, dass alle Rezepte in <div>-Elemente eingeschlossen sind, muss unser XPath-Ausdruck doch nur die in den <div>-Elementen (Kapitel) eingeschachtelten <div>-Elemente (Rezepte) finden.
So habe ich mir das gedacht.
Leider haben einige, aber nicht alle Kapitel des Kochbuchs Unterkapitel, und erst in diesen Unterkapiteln befinden sich die Rezepte, auf die wir es abgesehen haben; zum Kapitel "Fischgerichte" z. B. gehören die Unterkapitel "Seefische" und "Flussfische". Unser XPath-Ausdruck muss also angepasst werden: Unser XPath-Ausdruck muss je Kapitel unterscheiden, ob es Unterkapitel enthält oder nicht.
Ich frage mich wieder, ob die vom Deutschen Textarchiv vorgenommene Codierung besonders gut gelungen ist. Wäre es nicht sinnvoller gewesen, von einer Dokumentenstruktur auszugehen, in der alle Rezepte erst in Unterkapiteln stehen? Von der Codierung her wäre das einfach gewesen: Man hätte nur die Verschachtelung der <div>-Elemente konsequent durchführen müssen. Jetzt müssen wir einen etwas holprigen XPath-Ausdruck schreiben …
Der langen Rede kurzer Sinn: Das Kochbuch der Henriette Davidis enthält mehr als 1.200 Rezepte! Mammamia, bis die alle nachgekocht sind!
Norbert Luttenbergers Eintrag Nr. 4
Man könnte sagen, bis jetzt haben wir nur preprocessing betrieben: Uns liegen die Rezepte des "Praktischen Kochbuchs für die gewöhnliche und feinere Küche" von Henriette Davidis endlich als Text vor, der nur durch <head> und <p> tags strukturiert ist.
Wir können uns jetzt daranmachen, den Text weiter auszuzeichnen, oder, um in der Sprache der TEI Guidelines zu sprechen, unsere features of interest durch Einfügen spezieller tags hervorzuheben und damit der maschinellen Verarbeitung zugänglich zu machen. Was sich ja bei mehr als 1.200 Rezepten sicherlich lohnt. Mein spezielles Interesse richtet sich auf die kulinarischen Details aller Rezepte, und ich will anhand der "Suppe mit jungen Gemüsen" zeigen, wie ich vorzugehen gedenke.
Bevor ich loslege, eine Vorbemerkung: Andere Nutzer unseres Kochbuchs mögen andere Interessen haben. Vielleicht ist es für Philologen interessant, sich mit der Rechtschreibung im Rezept auseinanderzusetzen. Linguisten interessieren sich vielleicht für den Satzbau im Kochbuch. Da gibt es bestimmt noch viele andere Interessen.
Ich kann es mir im Moment nur schwer vorstellen, dass man Texte so umfassend auszeichnen kann, dass die Auszeichnung allen Interessen gerecht wird. Anders formuliert: Es gibt wahrscheinlich nicht die eine digitale Edition eines Textes, die allen Bedürfnissen gerecht wird; im Idealfall gibt es eine Kollektion von digitalen Editionen, die vielen Interessen gerecht wird.
Liebe Leserin, wie in jedem guten Roman gibt es jetzt auch hier kurz vor dem Ende der Geschichte noch eine Verzögerung, man könnte auch sagen: eine künstliche Verzögerung. In jedem guten Roman haben Held und Heldin, bevor sie sich endlich kriegen, noch einmal einen handfesten Krach, und in dieser Serie von Blogposts schreibe ich jetzt auf, was ich nicht will.
Im Netz bin ich auf eine langstielige Abhandlung [1] gestoßen, in der zunächst begründet wird, warum man ein Kochbuch nicht nur als eine Sammlung von Anleitungen zur Herstellung mehr oder weniger leckerer Gerichte auffassen dürfe, sondern darüber hinaus als ein kulturelles Artefakt begreifen müsse. Naja, ehrlich gesagt: Das war mir auch schon vorher klar. Um zu verdeutlichen, was sie damit meinen, vergleichen die Autoren dann ein Kochbuch von Nigella Lawson, einer englischen Erfolgsköchin, mit einem Kochbuch von Jamie Oliver, einem englischen Erfolgskoch. Mal davon abgesehen, dass aus dieser Auswahl kein besonders ausgeprägter international mind set spricht (an dessen Vorhandensein man im Nach-Brexit-England vielleicht überhaupt einige Zweifel anmelden müsste), kommen die Autoren zu der Erkenntnis, dass es schon ein Zeichen von unterschiedlicher Kultur ist, wenn Nigella Lawson in rückwärtsgewandter Manier bei jedem Rezept betont, dass auch ihre Mutter schon so gekocht habe, während Jamie Oliver sich lässig auf der Couch sitzend mit seinen Kumpels inszeniert. In ähnlicher Intention intoniert Lucy Scholes [2]: "… female TV chefs such as Smith and Lawson are still shown for the most part in their kitchens and their horizons rarely seem to stretch beyond the domestic sphere. Oliver, on the other hand, represents a new brand of chef who has taken off his apron and taken to the streets, rebranding himself as a social activist or even – in his own terms – a revolutionary."
Weder Mutter noch Couch noch Revolution sind meine features of interest. Mir geht es um Kulinarik, mich interessieren die Rezepte selber, nicht ihre Inszenierung. Mich interessieren Zutaten und Zubereitung. Und alles was dazu gehört. (Allenfalls könnte ich versucht sein, die Frage zu beantworten, ob denn die Rezepte von Jamie Oliver wirklich erkennbar anders komponiert sind als die von Nigella Lawson. Aber das will ich nicht aus den Kochbuch-Vorwörtern, -Klappentexten oder -Fotos herauslesen. Sondern aus den Rezepten.)
Ich entwerfe jetzt einmal eine kulinarische Auszeichnung für unser Gemüsesuppen-Rezept bzw. für das Kochbuch von Henriette Davidis. Leider kann ich mich dabei nur wenig an dem Beispiel orientieren, das in den TEI Guidelines auf den Seiten 1020ff. widergegeben ist: In diesem Beispiel wird ein Quelltext verwendet, in dem Zutatenliste und Zubereitungsanleitung bereits voneinander getrennt sind. Ich will im Unterschied dazu eine Auszeichnung angeben, die es ermöglicht, durch eine XSLT-Transformation aus dem vorhandenen Quelltext ein Rezept mit einer "heutigen Struktur" zu erzeugen. Dazu werde ich die im Text genannten Zutaten jeweils einzeln taggen. Was ich dafür brauche, sind einige "kulinarische tags". Da diese im TEI-Vokabular nicht vorgesehen sind, muss ich das TEI-Vokabular geeignet erweitern. Was dabei herauskommen wird? Nichts weniger als eine Auszeichnungssprache für kulinarische Editionen. Oder abgekürzt: eine culinary editions markup language (cueML, auf Deutsch passenderweise wie "Kümmel" auszusprechen).
Die Guidelines sehen die Möglichkeit zur Erweiterung des TEI-Vokabulars explizit vor:
"… the TEI scheme may be extended in well-defined and documented ways for texts that cannot be conveniently or appropriately encoded using what is provided. For these reasons, it is almost impossible to use the TEI scheme without customizing or personalizing it in some way."
Um diesen Blogpost nicht zu überfrachten, verzichte ich zunächst auf die Darstellung der Formalitäten, die eingehalten werden müssen, wenn neue tags kreiert werden sollen.

Ich versuche jetzt mal, die Idee die hinter dieser Auszeichnung steckt, zu verallgemeinern.
- Die tag names übernehme ich aus den properties des schema.org type recipe. (Den type recipe habe ich benutzt, um damit das <div> tag zu ersetzen, das in der ursprünglichen digitalen Edition ein Rezept eingeschlossen hat.) Damit habe ich (wenn ich die vererbten properties hier erst einmal nicht zähle) die folgenden properties:

- Die gewünschten tags sollen Fragmente des Originaltexts einschließen. Das bedeutet, dass diese tags nicht nur auf die jeweiligen Fragmente zeigen sollen, z. B. durch bestimmte Attribute. Damit wird eine ähnliche Vorgehensweise erreicht, wie sie auch bei der semantischen Auszeichnung mit schema.org verwendet wird. Das TEI tag <span> ist z. B. ein tag, mit dem auf bestimmte, identifizierbare Textabschnitte gezeigt wird. Anders als das von HTML her bekannte <span> tag umschließt es jedoch den Text nicht.
Hier ein XSLT-Script, das aus unserer TEI-codierten Suppe eine HTML-Suppe macht, die man besser lesen kann (naja, in diesem Satz sind wohl einige Buchstaben in die Suppe gefallen …).

Und so würde es der Chrome-Browser anzeigen:
Das ist doch schon nicht schlecht!
Ob ich allerdings diese Suppe jemals kochen werde, ja, das weiß ich wirklich nicht: Ich kann mir nicht vorstellen, dass ein in Boullion oder Wasser gekochter Kopfsalat wirklich gut schmeckt … But that's another story.
[1]: Douglas Brownlie, Paul Hewer & Suzanne Horne: Culinary Tourism: An Exploratory Reading of Contemporary Representations of Cooking. Consumption, Markets and Culture, Vol. 8, No. 1, March 2005, pp. 7–26.
[2]: Lucy Scholes: A slave to the stove? The TV celebrity chef abandons the kitchen: lifestyle TV, domesticity and gender. Critical Quarterly Special Issue: Food, edited by Lucy Scholes and Matthew Taunton, Vol. 53, Issue 3, pp. 44–59, October 2011.
Norbert Luttenbergers Eintrag Nr. 5
Ohne lange Vorrede schreibe ich jetzt auf, was mir an der Lösung, die ich im letzten Blogpost präsentiert habe, noch nicht gefällt:
- Das tag <recipeIngredient> schließt die Angabe für die Menge und für die Art der Zutat ein. Diese Angaben sollen aber separierbar sein. Dazu werde ich dem tag <recipeIngredient> eine Menge von Attributen hinzufügen, die eine Messung beschreiben. Eine solche Attributmenge ist in TEI enthalten, sie heißt att.measurement. Wir werden noch zu klären haben, auf welche Anzahl von Portionen sich eine Mengenangabe bezieht.
In gleicher Intention werde ich den tags cookTime und totalTime die TEI-Attributmengen att.duration und att.duration.iso hinzufügen. - Unschön ist auch, dass in unserer Zutatenliste eine Angabe im Dativ erscheint: "einem Stich Butter". (Hier macht sich der Dativ zwar nur bei der Mengenangabe bemerkbar, aber selbstverständlich kann man sich auch eine in das Rezept eingestreute Zutatenangabe vorstellen, in der auch die Art der Zutat in gebeugter Form angeführt wird.) Wir benötigen ein Attribut, in dem die Grundform des jeweils verwendeten Worts genannt wird. In der Sprachwissenschaft wird eine solche Grundform als Lemma bezeichnet.
- Ganz im Sinne des Semantic Web möchte ich die Zutaten als resources auffassen. Der RFC 3986 sagt:
"A resource is not necessarily accessible via the Internet; e.g., human beings, corporations, and bound books in a library can also be resources."
Damit können sicherlich auch die Zutaten zu einem Rezept als Ressourcen aufgefasst werden.
Im Semantic Web werden Ressourcen über URIs identifiziert, vgl. RFC 3986. Ich wünsche mir also eine Ressourcensammlung, in der alle denkbaren Zutaten aufgelistet sind und jede Zutat über einen Uniform Resource Identifier identifiziert wird. Man könnte es auch anders formulieren: Ich wünsche mir ein kontrolliertes Vokabular, das RDF-codiert ist. RDF bedeutet "Resource Description Framework", und in diesem Framework werden Ressourcen per URI identifiziert.
In einem solchen RDF-codierten kontrollierten Vokabular sollten nicht nur die Zutaten einfach aufgelistet sein. Zu jeder Zutat sollten auch die üblichen natürlichsprachlichen Bezeichnungen ("labels") in einer Menge von Sprachen genannt werden (die dann auch als Lemmata genutzt werden könnten, womit das oben postulierte Attribut entfallen könnte). Zusätzlich sollten für jede Zutat ggf. Verweise ("links") auf weitere Datenbestände enthalten sein, in denen sich z. B. Nährwertangaben oder andere Angaben finden lassen. Wenn all das, was ich mir wünsche, dann auch noch frei über das Netz zugreifbar ist, dann nennt man Linked Open Data (LOD).
Und jetzt treiben wir es noch ein bisschen weiter: Ich möchte in meinem RDF-codierten Vokabular nicht nur labels und links, sondern zusätzlich noch eine taxonomische Einordnung für jede Zutat, also z. B. "purslane (dt. Portulak) is-instance-of vegetable". (Zum Thema is-a und is‑instance-of vgl. die Dissertation und diesen Blogpost von Jesper Zedlitz.) Mit Taxonomien sind weitere Probleme verbunden, die ich aber hier nicht ausführlich diskutieren werden.
Du ahnst es, liebe Leserin, einen solchen Datenbestand bzw. eine solche Kombination von Datenbeständen habe ich nicht gefunden.
Ich werde in einem späteren Blogpost darauf zurückkommen.
Norbert Luttenbergers Eintrag Nr. 6
Heute nur ein ganz kurzer Blogpost: In ihrem Artikel "Flavor network and the principles of food pairing" zeigen die Autoren Yong-Yeol Ahn, Sebastian E. Ahnert, James P. Bagrow und Albert-László Barabási, was man über die Unterschiede zwischen der amerikanischen und der asiatischen Küche durch die kulinarische Analyse von ca. 56.000 (!) Rezepten herausfinden kann. Für jeden, der gerne kocht, ein must-read! Und für jeden, der sich mit big data beschäftigen möchte, ebenfalls ein must-read!
Vielleicht schaffen wir es ja, mit den Methoden, die die genannten Autoren vorschlagen, etwas Vergleichbares über deutsche Rezepte und ihre Veränderungen im Laufe der Zeit auszusagen.
Norbert Luttenbergers Eintrag Nr. 7
Immer noch machen uns die Mengenangaben in den Rezepten der Henriette Davidis gewisse Probleme.
Es gibt solche Mengenangaben wie "ein Stich Butter". Naja, für eine geübte Köchin ist zwar klar, was damit gemeint ist, aber diese Mengenangabe ist natürlich ganz und gar ungeeignet, wen man für das Suppenrezept eine Nährwertanalyse erstellen will. Da hilft nur eine exakte Angabe in einer definierten Maßeinheit.
In unserem Rezept für die "Suppe von jungen Gemüsen" werden wir die Zutat Butter deshalb wie folgt auszeichnen:
<recipeIngredient commodity="Butter" quantity="0.010" unit="kg">einem Stich Butter</recipeIngredient>
Der Wert des Attributs commodity bezeichnet das Lemma der im Rezept genannten Zutat. Woher ich dieses Lemma beziehe, muss ich noch klären.
Für alle anderen Zutaten gibt es keine Mengenangaben. Ja, es gibt nicht einmal eine Angabe, für wie viele Esser das Rezept gedacht ist. Da kann man nichts machen. Eine Nährwertberechnung kann hier nicht vernünftig durchgeführt werden.
In anderen Rezepten gibt es Mengenangaben pro Portion. Hier scheint es mir vernünftig, die Mengenangaben bei der Auszeichnung auf eine jeweils eine Portion umzurechnen.
Norbert Luttenbergers Eintrag Nr. 8
Ich habe noch einmal unser Rezept für die "Suppe von jungen Gemüsen" durchgelesen. Steht das wirklich drin, dass man den "Portulac" kochen soll? Ich kann es nicht fassen. Diese zarten, leicht säuerlichen Blättchen soll man wirklich in einer Suppe verkochen? Das ist doch ein leckerer Salat!!! Das geht ja gar nicht!
Eine Nachfrage bei einer Bekannten, die an der CAU im Bereich Ernährungswissenschaften arbeitet, hat das Missverständnis aufgeklärt: Die Bezeichnung Portulak wird sowohl für den hier links im Bild gezeigten Salat benutzt (der auch Postelein oder gewöhnliches Tellerkraut genannt wird), als auch für ein Gemüse, das im Deutschen als Gemüse-Portulak bezeichnet wird. Ein Bild vom Gemüse-Portulak habe ich nicht in meinem Fundus, deshalb hier ein Flickr-Bild von Alex "Skud" Bayley.


Warum diese ausführliche Diskussion? An dieser Stelle ist mir klar geworden, was eigentlich immer schon klar war: Das inhaltsorientierte Auszeichnen von Text ist keine "mechanische" Tätigkeit, im Gegenteil: Sie verlangt an vielen Stellen eine sehr gute Sachkenntnis. Oder wie man sagen würde: ein sehr gutes Domänen-Wissen.
In einem anderen Rezept habe ich gelesen, dass eine Zutat verwendet werden soll, die als "Scorzoner" bezeichnet wird. Was ist denn das, bitteschön? Kann bitte jemand helfen?
Norbert Luttenbergers Eintrag Nr. 9
Beim nochmaligen Durchlesen unseres Rezepts für die Suppe von jungen Gemüsen ist mir weiteres Problem aufgefallen, das ohne kulinarische Kenntnisse nicht gelöst werden kann. Was, bitteschön, ist den "Bouillon"?
Möglicherweise nicht ganz exakt kann man Bouillon als ein Halbfertigprodukt klassifizieren. D.h. eine Bouillon wird unabhängig von dem Gericht produziert, in dem sie schlussendlich verwendet wird. Und sie ist auch für sich allein konsumierbar.
Aber jetzt kommt die entscheidende Frage: Wer hat die Bouillon produziert?
Es könnte sein, dass Henriette Davidis vorschlägt, ein industriell gefertigtes Extrakt à la Liebigs Fleischextrakt zu verwenden, um eine Bouillon zu verwenden, oder sie könnte ein Rezept angeben, um eine Bouillon selbst zu kochen. Kochbuch-lesen ist angesagt!
(In diesem Kontext kann ich mir einen Lesehinweis nicht verkneifen: Unter http://geb.uni-giessen.de/geb/volltexte/2004/1381/pdf/SdF-2003-1_2b.pdf findet man die außerordentlich interessante "Geschichte von Liebigs Fleischextrakt" – sehr lesenswert!)
Beim Rezept für die "Krebssuppe" findet man den entscheidenden Hinweis: "Man kocht nach No. 1 eine gute Bouillon." Und was finden wir unter No. 1? Leider nicht etwa ein Rezept für eine Bouillon, sondern ein Rezept für eine "Klare weiße Rindfleischsuppe". In dieses Rezept ist das Rezept für die Bouillon hineingesteckt worden – die klare weiße Rindfleischsuppe wird auf der Basis einer Bouillon hergestellt, hat aber noch weitere Zutaten, z. B. "beliebige Klöße" – ein weiteres Halbfertigprodukt. Den Klößen hat Henriette Davidis ein eigenes Hauptkapitel gewidmet, nämlich in der vorliegenden Ausgabe das Kapitel L. (In der Ausgabe, die Jesper mir geschenkt hat, ist es das Kapitel O.) Naja, so könnte man sich wahrscheinlich durch das ganze Kochbuch hindurchhangeln …
Was bedeutet das für unsere kulinarische Analyse?
- Aus dem Rezept für die "Klare weiße Rindfleischsuppe" muss das Rezept für Bouillon herausgelöst werden. Dazu muss man den Text sehr, sehr genau lesen; es ist nicht auf Anhieb erkennbar, wo das eine Rezept in das andere übergeht. Kulinarischer Sachverstand ist gefragt. Dieses herausgelöste Rezept muss als solches erkennbar gemacht werden.
- Unser tag <recipeIngredient>, mit dem wir die "Bouillon" im Rezept für die "Suppe von jungen Gemüsen" ausgestattet haben, benötigt ein weiteres optionales Attribut, nämlich ein Attribut, das einen Verweis auf ein weiteres Rezept im Kochbuch der Henriette Davidis angibt.


Torstens Eintrag als SHK Nr. 1
Herr Luttenberger hat mich ermutigt eine Blog-Serie bezüglich meiner HiWi-Tätigkeit zu schreiben. Ich komme dem gerne nach; zu einem ist dies eine (ich bemühe mich) nett zu lesende Dokumentation. Zum anderen „nötigt“ es mich ab und an innezuhalten und zu überlegen, was ich niederschreibe/mache – und dies ist meist mit einem kritischen Hinterfragen verbunden, welchem manchmal tolle Aha-Effekte folgen, was immer gut ist. In der Hoffnung von vielen Aha-Effekten auch dieser Block-Titel. [Während der SHK-Zeit habe ich diesen Blog Blog - Tosten Knaufs Aha-Effekte genannt]
Grob gesagt ist das Ziel meiner Tätigkeit Henriette Davidises Kochbuch, welches bereits eingescannt und als XML-Format abgetippt hier vorliegt, maschinell auszuwerten und zu transformieren. Dazu muss das Buch zuerst durch Meta-Daten/XML-Tags angereicht werden. Anschließend können diese mittels XSLT beliebig transformiert werden. Das abschließende Ziel ist es, die Rezepte in einer Webseite in heute üblicher Form präsentieren zu können.
Torstens Eintrag als SHK Nr. 2
Meine erste Woche ist quasi rum und hier nun meine gewonnenen Erkenntnisse: Unten stehend ist beispielsweise das erste Rezept (eingefügt übrigens über notepad++ -> Erweiterungen NppExport -> copy RTF to clipboard und vorher mittels „str j“ die Zeilen gejoint sowie 4 Leerzeilen durch eins ersetzt und dann eine einzellige/-spaltige Tabelle drum) [Für die Webseite als Screenshot]

Angetreten bin ich mit der (naiven) Hoffnung, einen super schlauen Parser schreiben zu können, der automatisch um die Zutaten ein <cue:recipeIngredient>–Tag schließt. Doch schon das erste Rezept belehrte mich eines Besseren:
Fleisch muss später als Rindfleisch erkannt werden, da Rindfleischsuppe vom Schwein wahrscheinlich nicht gemeint ist. Für die Mengenangabe habe ich den Mittelwert von ¾ und ½ Pfund genommen. Scorzoner- […] Petersilienwurzel muss als Scorzonerwurzeln und Petersilienwurzel erkannt werden. Ersteres ist nicht mit Scorzonera (teuren Sommer-Trüffeln) zu verwechseln, sondern wahrscheinlich Scorzonera hispanica (Schwarzwurzeln). Zweiteres ist nicht etwa Petersilie, sondern ich kenne es unter Wurzelpetersilie.
Eine weitere Schwierigkeit ergibt sich bei Sachen wie. [Man]legt ihn in einen eisernen Topf, darauf ¼ Pfund in Scheiben geschnittenen rohen Schinken oder Sommerwurst. In der Zutatenliste sollte nicht getrennt voneinander roher Schinken und Sommerwurst auftreten, da nur eins von beiden benötigt wird. Daher habe ich ein <cue:recipeIngredientAlt>-Tag hinzugefügt.
<cue:recipeIngredientAlt><cue:recipeIngredient quantity="0.1" unit="kg">rohen Schinken</cue:recipeIngredient>, oder <cue:recipeIngredient>Sommerwurst</cue:recipeIngredient></cue:recipeIngredientAlt>
Damit das XML-Dokument wieder valide ist, muss nun die relax ng-Grammatik angepasst werden. Herr Luttenberger hat mich glücklicherweise rechtzeitig darauf hingewiesen, dass die cueML.rng-Grammatik automatisch erstellt wurde/wird und dass es daher sehr ungünstig ist, die Datei manuell zu ändern, falls sie (automatisch) geändert wird. Daher habe ich die Grammatik in cueML_with_extension.rng erweitert.
Zurück zu dem <cue:recipeIngredientAlt>-Tag. Was macht man nun bei sowas wie […] und schüttet mit Zitronenschale, Charlotten oder Zwiebeln […]. Sind eins von den 3 oder Ersteres und Charlotten oder Zwiebeln gemeint? Schwierig – da ich mir Zitrone mit Zwiebeln nicht so gut vorstelle, habe ich mich für die erste Variante entschieden, aber sicher bin ich mir nicht.
Ein weiteres Problem wurde mir bei mit geschmolzener Butter, Senf, fein gehackter Petersilie (jedoch jedes besonders) oder mit einer sauern Eier-Sauce und Kartoffeln zur Tafel gegeben klar. Es ist entweder Butter, Senf, Petersiele oder Eier-Sauce gemeint und NICHT Butter oder Senf oder Petersiele oder Eier-Sauce. Als Workaround finde ich <ab>-Blöcke (anonym block) ausreichend.
mit geschmolzener <cue:recipeIngredientAlt><ab><cue:recipeIngredient >Butter</cue:recipeIngredient>, <cue:recipeIngredient>Senf </cue:recipeIngredient>, fein gehackter <cue:recipeIngredient>Petersilie </cue:recipeIngredient> (jedoch jedes besonders)</ab> oder mit einer <ab><cue:recipeIngredient>sauern Eier-Sauce</cue:recipeIngredient><link target="#P-19 #P-20" /></ab></cue:recipeIngredientAlt> und <cue:recipeIngredient>Kartoffeln</cue:recipeIngredient> zur Tafel gegeben.
Gerade fällt mir dabei ein: Die cueML-Grammatik selber um ein Tag (<cue:recipeIngredientAlt>) zu erweitern ist zwar relativ leicht und geht relativ schnell. Allerdings ist es dann nicht mehr Standardkonform. Wahrscheinlich sollte man den Machern von cueML das Problem schildern. Sie haben vielleicht bereits ein Workaround für das Problem oder könnten den Standard für alle erweitern.
Also habe ich die ersten drei Tage Parser „gespielt“ und nichts Anderes gemacht, außer Zutaten getagt – yay, was nen Spaß. Dieser wird auch nicht dadurch erhöht, dass die Rechtschreibung sowie Grammatik aus heutiger Sicht gewöhnungsbedürftig sind. Ich hoffe sehr, dass ich mir sie nicht ausversehen zu eigen mache.
Gott sei Dank kam Herr Luttenberger gestern zu mir und hat mir die Pläne für das Projekt/meine Arbeit genauer vorgestellt:
Als Ergebnis davon habe ich eine erste Bastelei / Vertraut machen mit XSLT / Plausibilitätsüberprüfung in recipes extracted cueML to html.xsl gebastelt – eine willkommene Abwechslung, auf die ich mich mit Freude gestürzt hatte. Das Ergebnis sieht wie folgt aus:

Eine Spielerei, die ich schon viel früher hätte machen sollen. Ganz im Sinne der iterativen Entwicklung 1-3 Rezepte tagen und dann überprüfen, wie das Ergebnis aussieht. Ich bilde mir ein, dass das Tagen mit dem Wissen, dass man die Daten wie folgt sinnvoll extrahieren kann, viel befriedigender ist – diese These werde ich demnächst validieren können, da es noch mehr als genug Rezepte zu tagen gibt. Des Weiteren ist mir so aufgefallen, dass das <cue:recipeIngredientAlt>–Tag benötigt wird. Vorher hatte ich nur das Gefühl, dass es nicht ganz stimmt – jetzt hingegen bin ich, wenn wahrscheinlich auch nur vorerst, wieder zufrieden mit den Tags. Das vorerst ist aber nicht schlimm, denn wenn ich (oder wer anders) nicht mehr zufrieden ist, ist das ein Zeichen davon, dass man etwas gelernt hat. Aus meiner Sicht der Traum oder zumindest das Ziel von jedem Studenten! *Notiz an mich selbst: Das nächste Mal einfach selber auf die Idee kommen einmal so eine Plausibilitäts-Spielerei durchzuführen*
Was ich noch vergessen hatte, aber sicherlich dokumentationswürdig ist, ist die Datei Umrechnung quantity.txt. Dort habe ich Umrechnung wie 1 Stich Butter = 10g oder 1 EL Mehl = 10 g vorgenommen, damit ich diese nicht immer neu suchen muss und sie auch einheitlich sind.
Was mich demnächst beschäftigen wird:
- Natürlich mehr Zutaten tagen – jetzt wo ich jedoch gesehen habe / selbst nachvollzogen habe, dass das jetzige Schema Sinn und Verstand hat und ich Abwechslung zwischen durch habe, eine akzeptable Tätigkeit (man möge mir mein Misstrauen verzeihen, dass ich Sachen erst glaube, wenn ich sie selbst nachvollzogen habe – wir sind hier ja in einer Universität und nicht in der Kirche :-P ).
- Mich mit der geplanten Webseite genauer beschäftigen. Das Ziel ist eine formvollendete wie Vulkaneifelhaus.com, welche optional mit Wix gebaut werden kann.
- Beim Tagging Ungereimtheiten zu entdecken/verbessern. Z. B. sind mir folgende Sachen noch aufgefallen:
- Das Rezeot P-3 sieht im wesentliche, wie folgt aus: Wie die vorhergehende, nur mit weiß gebranntem Mehl und Bouillonzubereitet, die Nelken bleiben weg. Mit einem link zum vorherigen könnte man die Zutaten von dort übernehmen. Allerdings würden dann auch Nelken auftauchen, was ja explizit nicht geplant ist. Dementsprechend bräuchte man eine Möglichkeit, gelinkte-Zutaten zu entfernen. Dies wäre zum Beispiel über ein exclude-Attribute im link-Tag möglich.
- Ich habe mich bei dem Beispielfall aus Rezept P-33 junge Sahne, in Ermangelung derselben frische Milch dazu entschieden, Milch nicht als Zutat zu tagen, da es nur eine Ersatz-Zutat ist. Allerdings geht dadurch die Information verloren, dass Sahne augenscheinlich eine nicht selbstverständlich verfügbare Zutat darstellt und man als (billigere?) Alternative mit Milch gekocht hat. Gerade fällt mir auf, dass das bereits eingeführte <cue:recipeIngredientAlt>–Tag dafür eine gar nicht so schlechte Lösung wäre.
- Das XSLT zieht zurzeit die Zutaten nur aus den <p>-Tags. Manchmal steht eine Zutat allerdings nur im <head>-Tag und ist deswegen dort getaggt. Das XSLT muss dahingehend noch angepasst werden.
- P-6 oder P-61 sind jeweils 2 unterschiedliche Rezepte innerhalb einem recipe-Tag. Eine Zutatenliste, welche beide Rezepte umschließend, finde ich irgendwie nicht akkurat.
- Mengenangabe 8 Pfennig Weißbrot verstehen
Also insgesamt sehr viel tun und neben dem (stupidem) Tagging auch viel spannende Abwechslung. Insbesondere freue ich mich auf das Basteln der Webseite und das zusammentragen der Rezepte / „Ernten des Taggings“ – Mal schauen wie weit ich komme. In diesem Bereich könnte ich mir auch eine spannende Master-Arbeit vorstellen.
Torstens Eintrag als SHK Nr. 3
Der erste Monat ist um und von den 150 Stunden habe ich bereits 75 geleistet (Viele Stunden gingen auch in die Webseite „Todesopfer durch Luftangriffe“ – Eine schicke Webseite, an der ich viel JavaScript lernen durfte). Zeit einmal zusammenzutragen, auf was für Schwierigkeiten ich beim Kochbuch gestoßen bin und darüber zu sinnieren, wie man sinnvoll weitermacht.
Zunächst einmal Punkte, bei denen ich mir unsicher bin, ob ich sie durch mein Tagen korrekt erfasst habe:
- Ich bin mir unsicher, ob Beilagen für Zutaten wichtig sind. Ich tendiere dazu, dass sie frei wählbar sind und daher nicht zur Zutatenliste beitragen. Also habe ich sie bis jetzt nicht getagt. Falls wir sie doch tagen wollen, sind „Beilage“ und „dabei“ gute Stichwörter um im Text nach ihnen zu suchen.
- Vielleicht ist ein eigenes Tag für Beilagen sinnvoll. Ich bin überrascht, dass es das nicht im schema.org/Recipe zu geben scheint.
- Bis jetzt habe ich beispielsweise drei bis vier Eier wie folgt getagt: drei bis vier <cue:recipeIngredient unit="3.5">Eier</cue:recipeIngredient>. Damit ist die Information, dass es 3-4 Eier sind, nicht mit eingetagt. Es wie folgt zu machen, finde ich im Nachhinein besser: <cue:recipeIngredient unit="3.5">drei bis vier Eiern</cue:recipeIngredient>. Auch könnte man sich überlegen unit="3-4" zu verwenden.
- Ich habe Zweifel, ob cue:cookTime später richtig ausgewertet werden kann. Bei Rezept D-58 steht beispielsweise wenigstens 2 Stunden, was ich schwer zu quantifizieren finde…
Oder bei Rezept P-64 habe ich ein „einsames“ <cue:cookTime dur-iso="PT15M">¼ Stunde</cue:cookTime> getagt, welches später nochmal durchgekocht wird. Die gesamte Kochzeit ist also länger als die ¼ Stunde. Mir ist auch nicht klar, wie die Zugehörigkeit der ¼ Stunde maschinell zuordenbar sein soll. - Beispielsweise bei Rezept D-58 steht Fehlt ihm die gewünschte Süße, so wird zeitig ein Stück <cue:recipeIngredient>Zucker</cue:recipeIngredient> dazu gethan, so wie beim Anrichten die Brühe mit etwas <cue:recipeIngredient>Kartoffelmehl </cue:recipeIngredient> gebunden gemacht. Zum einen ist unklar, ob das Binden mit Kartoffelmehl nur erfolgen soll, wenn es nicht süß genug ist. Zum anderen bin ich mir nicht sicher, ob der Zucker als Zutat anzugeben ist. So etwas wie recipeOptionalIngredient wäre zutreffender als recipeIngredient.
- Bei Rezept D-74 heißt Kartoffeln mit verschiedenen Saucen. Ist das überhaupt ein richtiges Rezept? Ist es sinnvoll verschiedene Saucen mit dem gesamten Saucen Kapitel zu verlinken?
- Kochen habe ich bis jetzt nicht mit <cue:cookingMethod> getagt. Allerdings finde ich es mittlerweile inkonsequent z. B. braten zu tagen und kochen nicht.
- Beispielsweise bei Rezept B-89 steht Diese wird eben so gemacht <link target="#B-88"/>, nur lasse man statt Hollunderblüthen […]. Wenn die Zutaten aus B-88 hinzugenommen werden, werden Hollunderblüthen übernommen, was ja explizit nicht gewünscht ist. Dementsprechend sind Metadaten notwendig, um bei link zu entscheiden, welche Zutaten zu übernehmen sind.
- Aus Regeln beim Zubereiten der Klöße ergibt sich für alle Klöße (L-Rezepte), bei denen nichts Anderes angeben ist, eine Kochzeit von 10-15min. Eigentlich sollte man diese Information dann auch überall entsprechend eintagen, was ich noch nicht getan habe.
Ein paar triviale Sachen die mir aufgefallen sind:
- Ab und an begegne ich noch einem f, welches lieber ein s wäre. Manchmal allerdings auch ss, welche lieber ff wären wie bei Eßlössel. Bei diesen Fällen versuche ich stets die entsprechenden Buchstaben zu ihrem Glück zu verhelfen.
- Die G-Rezepte haben als Typ Eier-Milch-undMehl-Speisen Ich nehme an, dass da ein Leerzeichen fehlt.
Insgesamt habe ich das Gefühl, dass es schwer ist, Davidis’s sehr unstrukturierte Rezepte zu tagen. Daher habe ich den Verdacht, dass sich noch herausstellen wird, dass ich manche Sachen lieber anders getagt hätte.
Es wäre sicherlich nicht optimal, zunächst alle Rezepte zu tagen und beim weiterem Vorgehen festzustellen, dass man manche Sachen lieber anders getagt hätte. Dann müsste man nämlich alle Rezepte korrigieren. Ich finde es schlauer, zunächst das weitere Vorgehen an den bisherigen Rezepten durchzuexerzieren (das spezifizieren der Zutaten durch den Bundeslebensmittelschlüssel, sowie die Webseite). Diese sind immerhin bereits einige hundert. Ergeben sich dabei bezüglich der Tags Aha-Effekte, können diese gleich bei den restlichen Rezepten berücksichtigt werden.
Randnotiz: Beim Schreiben ist mir nebenbei aufgefallen, dass ich oft Wörter wie tagen, getagt, usw. verwende. Leute die mich gut kennen, würden dies sicherlich mit „typisch Torstisch“ kategorisieren. Ich gelobe über die richtige Verwendung/Übersetzung zu ich tage nachzudenken.
Das Tagen ist übrigens eine Arbeit, die bei mir nicht die größten Freudegefühle auslöst. Dazu ist sie gar nicht so stupide, wie man vielleicht denken mag. Wie bereits erwähnt ist die Struktur von der lieben Frau Davidis nicht gut, was definitiv eine Untertreibung ist. Das Tagen ist auch deutlich anstrengender als gedacht und nimmt mehr Zeit in Anspruch. Ein Lichtblick ist dieser Artikel über Extracting Structured Data From Recipes Using Conditional Random Fields. Hier ist deren GitHub Repository. Daraus ist die Idee geboren eine Texterkennung für unser Kochbuch zu schreiben. Gelingt dies, können viele ähnliche Kochbücher mit deutlich weniger Aufwand durch Metadaten angereichert werden. Auch wenn ich noch keine Ahnung davon habe, freue ich mich darauf, mich in diesen Themenbereich einzuarbeiten und viele neue, spannende Sachen und Algorithmen zu lernen.
Wie im Artikel erwähnt, hat der Algorithmus auch Fehler in den von Menschen getagten Rezepten gefunden. Wenn die Texterkennung gut wird, wird diese sicherlich auch den ein oder anderen Fehler bei mir finden (wer will schon ernsthaft behaupten, dass er fehlerfrei ist?). Wenn die Texterkennung unterschiedliche Zutaten wie ich tagt, dann kann dies eventuell sogar einen Hinweis liefern, wo das Tag-Schema noch nicht voll ausgereift ist.
Also nächste To-dos ergeben sich für mich damit:
- Besprechen wie die Zutaten spezifiziert werden (Anbindung an den Bundeslebensmittelschlüssel)
- Überlegen wie die Webseite aufgebaut wird und wie welche Daten dargeboten werden
- Datenbank für finale Rezepte?
- Nur client-seitige Technologien oder auch Server?
- Literatursuche/einarbeiten in Masterarbeit/automatische Texterkennung (von Kochbüchern)
(Literatursuche - aufgrund von freundlichen Winks mit dem Eisernen Zaunpfahl fett geschrieben)
Torstens Eintrag als SHK Nr. 4
Diesen Blockeintrag werde ich in zwei Teile aufteilen. Hier erläutre ich kurz den statischen Datenflow von dem recipes extracted cueML.xml zu der Webseite, welcher sich in drei Teile aufspaltet:
- Ein Inhaltsverzeichnis aufstellen
- Die Rezepte extrahieren
- Die Verweise einbauen
Im zweiten Teil werde ich meine Erkenntnisse zum Tag-Schemata zusammentragen. Ich denke, ich habe nun anhand der Beispiel-Webseite viel griffiger verstanden, was bis jetzt an meiner Zufriedenheit gekratzt hat. Aber zunächst kommt hier der erste Teil:
1. Ein Inhaltsverzeichnis aufstellen
Das Inhaltsverzeichnis wird mittels XSLT in einem JSON-Objekt zur Verfügung gestellt. Das JSON-Objekt ist ein Dictionary, welches pro Rezept-Kategorie ein Dictionary anlegt. Dieses besteht aus rcp-id und Rezept-Name Paaren. Wenn die vorherige Rezept-Kategorie eine andere ist, als die aktuelle, legt das XSLT eine neue Kategorie an. Daher ist es wichtig, dass die Rezepte sortiert nach ihrer Kategorie vorliegen. Da die Rezepte ggf. danach vorsortiert werden können (was sie z.Z. bereits sind), stellt dies keine Einschränkung dar. Aus diesem JSON-Objekt kann dann eine Navigationsleiste erstellt werden.

2. Die Rezepte extrahieren
Für jedes Rezept wird mittels XSLT ein html-Dokument Namens rcp-id.html erstellt, welches via JS in die Webseite eingebunden werden kann.
Das html-Dokument besteht aus 3 Spalten. In der ersten Spalte ist eine Zutatenliste, in der 2. die Anleitung und in der 3. ein Bild. Für jedes link-Tag wird ein beginnend bei eins nummerierter Verweis angezeigt.
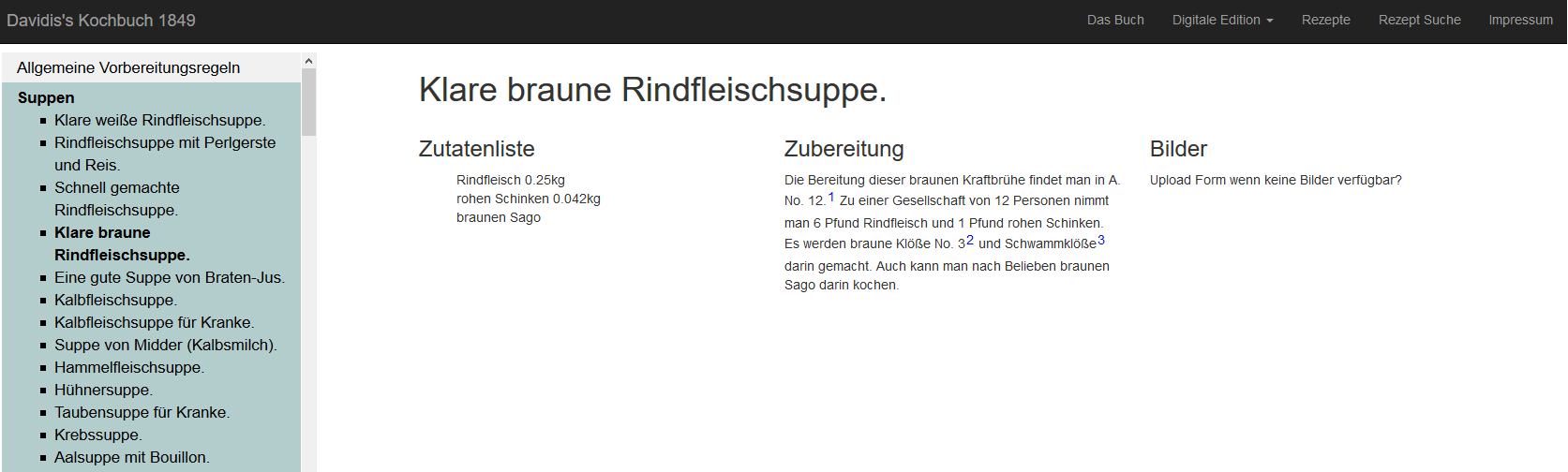
3. Die Verweise Einbauen
Die Verweise erscheinen bei Klick in einem transparenten Popup. Bei den Verweisen werden zwei Kategorien unterschieden:
- Wenn auf ein ganzes Rezept verwiesen wird, wird rcp-id.html geladen.
- Ansonsten wird der Text zwischen dem Start-tag bis zum End-tag geladen.
Technisch umgesetzt wird das, in dem die Rezepte mittels extract recipes for website.xsl in ein JSON-Objekt wie untenstehend umgewandelt wird.

Torstens Eintrag als SHK Nr. 5
Hier nun meine gewonnenen Erkenntnisse bezüglich des Tags-Schemas. Allgemein würde ich sagen, dass ich bis jetzt nicht ganz zufrieden war, da ich bei der Aufarbeitung der Meta-Daten sofort die Verwendung in der Webseite im Kopf hatte. Ganz im Sinne vom Software Engineering Goal Seperation of Concerns sollte dies jedoch ein komplett eigener Concern sein, welcher auf saubere Meta-Daten aufbaut. Dementsprechend sollten meiner Meinung nach die Meta-Daten das Dokument exakt wiedergeben und nicht bereits Transformationen wie Maß in Liter vornehmen. Bevor ich meine Erkenntnisse genauer erläutern will, möchte ich festhalten, dass ich nun das Gefühl habe, das Kochbuch sinnvoll tagen zu können und freue mich über meine Lernkurve. Auch wenn dies damit verbunden ist, dass ich meine Tags wahrscheinlich noch einmal überarbeiten muss (yay, noch mehr tagen :P ).
- Die Quantifizierungseinheiten würde ich nicht Übersetzten, sondern im Original übernehmen. Ich sehe darinnen mehrere Vorteile:
- Einheiten wie 1 Loth, oder für 4 Pfennige geriebenes Weißbrod, welche orts- und zeitabhängig sind (und die ich daher nicht berücksichtigt habe), können so angegeben werden. Dem menschlichen Leser geben diese Einheiten auch eine ungefähre Größenordnung, wenn diese in die Zutatenliste übernommen werden. Darüber hinaus können diese Einheiten auch ggf. später nach gründlicher Recherche leicht voll automatisch in heute übliche Maße übersetzt werden.
- Wurde eine Einheit hingegen manuell falsch übersetzt, so ist das nachträgliche Korrigieren nicht trivial. So schreibt Frau Davidis z. B. als Anmerkung in ihrem Inhaltsverzeichnis, dass 1 Maß gleich 1 Quart ist. Bis jetzt habe ich 1 Maß mit 1l übersetzt. Ein erster Blick auf Wikipedia zeigt, dass ein Quart im deutschsprachigen Raum gar keine eindeutige Maßeinheit war/ist. In Breslau hat man z. B. unter einem Maß nur 0.69l verstanden. Eine automatische nachträgliche Anpassung von allen Liter-Einheiten ist aber nicht zielführend, da ich z. B. ein Glas Rum stets mit 0.2l übersetzt habe und ein Weinglas mit 0.3l, welche nicht an die Maß-Umrechnung gebunden sind. (Evntl. will man später auch diese Übersetzungen korrigieren, was kein Problem wäre, wenn die unit=“Weinglas“ mit quantity=“1“ gewesen wäre.
- 1 Pfund haben wir als 1 kg festgelegt. Ich bin mir nicht sicher, ob das stimmt (diese Übersetzung ergibt sich zumindest nicht aus Wikipedia).
- 1 EL Reis habe ich mit 15g übersetzt. Da jedoch nur kg als Einheit zugelassen ist, steht in der Zutatenliste Reis 0.015kg, was ich persönlich unschön finde. 15g oder 1EL fände ich angenehmer zu lesen.
- 3.5 Eier in einer Zutatenliste zu lesen, finde ich gewöhnungsbedürftig. Abgesehen davon gehen durch den Mittelwert bei variablen Angaben Informationen verloren. So sind z. B. aus meiner Sicht 4 Eier etwas Anderes als 3-5 Eier.
- Ich finde es auch nicht intuitiv in der Zutatenliste andere Einheiten als im Text zu lesen. Stattdessen könnte man die original und heute übliche Einheit anzeigen, oder zu einer Umrechnungsübersicht verlinken.
- Ich habe das Gefühl, dass manche relevanten Informationen außerhalb der Rezepte zu finden sind. Zum Beispiel dass, wie bereits erwähnt, Frau Davidis unter einem Maß ein Quart versteht. Oder dass alle Klöße, sofern nichts Anderes angeben ist, 10-15min kochen sollen. Daher fände ich es sinnvoll, alle „allgemeinen Vorbereitungsregeln“ und Ähnliches mit auf die Webseite zu übernehmen. Es schadet wahrscheinlich auch nicht, einmal sämtlichen Text auf z. B. im Inhaltsverzeichnis versteckte Anmerkungen zu lesen (auch wenn dies Arbeit macht/ist).
- Da ich nicht sehe, wie die cooktime sinnvoll zugeordnet werden kann, würde ich sie komplett weglassen – Für schlaue Ideen bin ich immer dankbar; ich bin ja u. A. hier um etwas zu Lernen
- Rezept A-12 ist z. B. für 12 Personen gedacht. Daher habe ich die Zutaten manuell auf p.P. runtergerechnet, was ich im Nachhinein für nicht clever erachte. Abgesehen von unnötigen Rundungsfehlern, sind die Mengenangaben so sehr klein, was insbesondere daher überrascht, dass die meisten Rezepte nicht auf p.P. runter gerechnet sind. Stattdessen hätte ich die Originalmenge nehmen und zusätzlich das Element recipeYield verwenden sollen.
- Bei Beilagen war ich mir unsicher, ob diese als Zutaten zu tagen sind, oder nicht. Ich denke, sie in das bisherige Schema reinzupressen ist der falsche Ansatz. Diese sollten stattdessen als das getagt werden, was sie im Dokument sind (Beilage / supplement). Später kann dann überlegt werden, ob diese in der Zutatenliste auftauche, einen eigenen Überschrift / Liste Beilagen kriegen, ob sie in eine Kalorien-Berechnung mit reinzählen, etc…
- Gleiches gilt für Zutaten, welche z. B. je nach Geschmack verwendet oder weggelassen werden können. Da diese im Dokument optional sind, sollten sie als optionale Zutaten getagt werden und die spätere Verwendung kann diese dann wie gewünscht interpretieren. Sie als Zutaten zu tagen oder gar nicht zu tagen (wie ich es bis jetzt leider gemacht habe) ist ein unnötiger Informationsverlust.
- Für eine vollstände Zutatenliste ist das bisherige link-Tag noch nicht ausreichend. Im Text ist die Information, ob alle, keine, oder eine Teilmenge der Zutaten zu übernehmen sind verborgen. Diese Information könnte man beispielsweise in einem includeIngredients-Attribut maschinell lesbar machen.
Des Weiteren habe ich noch folgende, offene todos im Kopf:
- Beim BLS habe ich aus Interesse einmal nachgefragt, in wie weit man ihn für eine Akademische Arbeit verwendet darf. Die Antwort würde ich so interpretieren, dass man Nährstoffinformationen extrahieren darf, solange man den BLS nicht öffentlich stellt. Angaben ohne nachvollziehbare Quelle anzugeben finde ich jedoch sehr unbefriedigend / fragwürdig, so dass ich gerne auf den BLS verzichten würde. Ich denke, dass ich meine HiWi-Stunden alleine mit dem Tagen mehr als voll kriege und halte es daher für vertretbar, die Extraktion der Nährstoffe als eigenes (erst einmal nicht mein) Thema aufzufassen.
- Für die Webseite wäre wahrscheinlich ein kurzer Lebenslauf von Frau Davidis nett, so wie ein Paar Informationen zum Buch wie z. B. wie viele Auflagen es gab, wie viele Exemplare verkauft wurden, etc…
- Informationen zur digitalen Verarbeitung zusammentragen. Dies ist wahrscheinlich in kurzer Form für meine Master-Arbeit sowieso sinnvoll, so dass ich das noch tun wollte.
Torstens Eintrag als SHK Nr. 6
Hier schreibe ich Notizen für den digitalen Blog der Webseite auf. Sie sind zur Strukturierung meiner eigenen Gedanken gedacht.
Metadaten:
- Semantic web, application orchestration, …
Aber eigentlich nur tags (Mit Ontologie / wohldefinierten Vokabular) - http://teibyexample.org/modules/TBED00v00.htm - Beispiel kursiv für Eigenname, oder wichtig, oder Verweis, oder …
- Mensch erkennt die Bedeutung aus dem Kontext / intuitiv
- Computer braucht Metadaten zum Verstehen codiert durch Tags / ML / Ontologie
TEI:
- Text Encoding Initiative (TEI) 1987 gegründet, seit 2000 als TEI-Konsortium organisiert
- Nicht gewinnbringend orientierte Forschungsorganisationen
- Standard und Guidelines / best practise für die Digitalisierung von Texten mit Hauptaugenmerk auf soziale und linguistische Forschung
- Metadaten-Tags: Erscheinungsjahr, Autor, Herausgeber, …
- Strukturelle-Tags: Kapitel, Überschrift, Hervorhebungen, …
- TEI Guidelines := ML + Doku
- „It is often observed in the TEI community that there is no one correct way to encode any given text. Different projects and researchers will analyze texs differently“ (http://www.tei-c.org/Support/Learn/intro.xml)
- 22 Module (core, header, textstructure und tei immer benutzen)
- ODD-Format (One Document Does it All) beschreibt individuelles TEI-Schema (verwendete Module und sonstige Anpassungen) -> Aus dem ODD wird ein Schema geparst (z. B. rng) (unser ODD ist cueML.xml)
Der Beginn einer Master-Arbeit
So; Meine Master-Arbeit ist nun angemeldet. Sie trägt den Titel Extracting recipe ingredients from cookbooks (bzw. bei der Abgabe nun Definition der TEI-basierten „culinary editions Markup Language“ (cueML), Bewertung von Verfahren für die automatische Extraktion von Zutatenlisten aus Rezepten und die Auszeichnung des „Praktischen Kochbuchs für die gewöhnliche und feinere Küche“ von Henriette Davidis (1849) - eventl. habe ich da etwas mehr gemacht, als vorgenommen :) ). Ich muss gestehen, dass der Title der ersten Präsentation nach genauerer Recherche einem Irrtum zugrunde liegt. Ich war der festen Überzeugung, dass das erste Kapitel von der Hobbit Der Beginn einer Reise heißt. Die Assoziation mit meiner Master-Arbeit auf ein ungewisses Reise zu gehen, neuen Problemen zu trotzen und neue Erfahrungen, Werkzeuge, etc zu sammeln, fande ich sehr schön. Daher der Title Der Beginn einer Master-Arbeit. Als ich beim nächsten Besuch meiner Eltern im Buch nochmal nachschlagen konnte, musste ich feststellen, dass das erste Kapitel Ein unerwartetes Fest heißt. Na ja, shit happens. Ich hoffe die Assoziation nichtsdestotrotz geweckt zu haben. Folgend also meine erste Präsentation:
Download der Präsentation als PDF
Irrlichter
Ich zitiere aus Wikipedia: "Irrlichter, auch Sumpflichter oder Irrwische (In manchen Fällen wird auch der lateinische Ausdruck ignis fatuus, übersetzt etwa „Narrenfeuer“, verwendet)". Eine Präsentation mit so einem Titel lässt nichts Gutes erahnen - und in der Tat; erst mit dieser Präsentation habe ich so richtig gemerkt, dass die Vokabular-Bildung echt schwierig ist und ein wesentlicher Bestandteil der Master-Arbeit.
Download der Präsentation als PDF
Heraus aus dem Sumpf
Dieser Titel hört sich doch schon gleich viel positiver an! Nach dem ich einmal das Problem verstanden habe - dass das Vokabular ein schwieriges Problem ist - konnte ich es selbstverständlich auch niederringen...
Download der Präsentation als PDF
Ritter und Fabelwesen
Inzwischen kann ich schon auf eine sehr lange Reise zurück blicken: Nach dem Aufbruch (viel Literatur-Recherche), Verirrungen im Sumpf (kämpfen mit dem Vokabular) und dem herausfinden aus dem Sumpf ("bezwingen" des Vokabulares) bin ich nun endlich auf Ritter und Fabelwesen gestoßen. Was ich damit meine?
Als Informatiker träume ich natürlich nicht von Rittern, sondern vom Programmieren! Nach der vielen Vorarbeit habe ich mich nun endlich so richtig mit dem Programmieren beschäftigt. Allerdings hat sich der erste Ansatz mittels Conditional Random Fields als nicht zielführend herausgestellt. Da insgesamt schon sehr viel Zeit verstrichen ist (und ich auch schon sehr viel erlebt/geschafft habe), muss ich einsehen, dass das perfekte Programm im Rahmen dieser Arbeit so real ist, wie ein Drache, oder Gift-Gnom. Aber ich werde mein Bestes geben, dass der mir nachfolgende Student solche Fabelwesen, aufbauend auf meiner Arbeit, finden kann :-P
Download der Präsentation als PDF
Das Festmahl zum Schluss (natürlich nach Davidis' Kochbuch zubereitet)
Zum Schluss einer guten Reise wird immer gefeiert - und diese Reise war selbstverständlich gut! Dazu gehört natürlich ein ordentliches Festmahl. Ein Gericht aus Davidis' Kochbuch zu kochen liegt da auf der Hand. OK, ordentliche Festmahl ist vielleicht ein bisschen übertrieben, aber dieser Auflauf von saurer Sahne mit Obst hört sich interessant an, ist schnell gemacht und kannte ich so noch nicht. Das Ergebnis ist unten im Bild zu sehen. Geschmackliche Bewertung - ganz nett.

Wirklich zum Schluss nun meine Abschluss-Präsentation. Um einmal die Möglichkeiten der interaktiven Grafiken einer Webseite auszunutzen, habe ich für diese keine klassische Power-Point-Präsentation gebastelt, sondern hier eine interaktive Grafik vorgestellt. Diese zeigt die einzelnen Arbeitsschritte der gesamten Arbeit vom gedruckten Buch bis hin zur digitalen Edition.