Nachdem wir im vorherigen Abschnitt eine Transkription zu Davidis' Kochbuch erarbeitet haben, wollen wir uns nun damit beschäftigen, wie wir die Informationen aus dem Buch automatisch auswerten können. Dafür gehen wir zuerst darauf ein, wie Informationen zugänglich gemacht werden können. Anschließend betrachten wir existierende Auszeichnungssprachen, die Informationen aus unserer Domäne zugänglich machen.
Informationen zugänglich machen
„The key to utilizing the knowledge of an application domain is identifying the basic vocabulary consisting of terms or concepts of interest to a typical user in the application domain and the interrelationships among the concepts in the ontology.“
Eine Ontology wiederum ist ein „set of interest in a particular information domain and the relationships among them“. Ein wohldefiniertes Vokabular kann demnach eine Ontology sein. Dieses kann beispielsweise durch ein Extensible Markup Language Schema (XML Schema) definiert werden . Alle Informationen eines XML Dokumentes nach einem Schema können dann automatisch extrahiert werden.
Das Ziel ist somit, die Rezepte aus Davidis' Kochbuch in einer Auszeichnungssprache zu erfassen, dessen Vokabular und Beziehungen untereinander wohldefiniert sind und die den Bereich einer kulinarischen Analyse abdeckt. Das Erfassen von Informationen durch eine Auszeichnungssprache nennen wir auszeichnen. Folgend stellen wir einige Auszeichnungssprachen für unsere Koch-Domäne vor.
TEI: Text Encoding Initiative
TEI ist ein Standard, um Texte digital darzustellen, mit dem Schwerpunkt die Texte für Geistes- und Sprachwissenschaften maschinenlesbar zu machen.
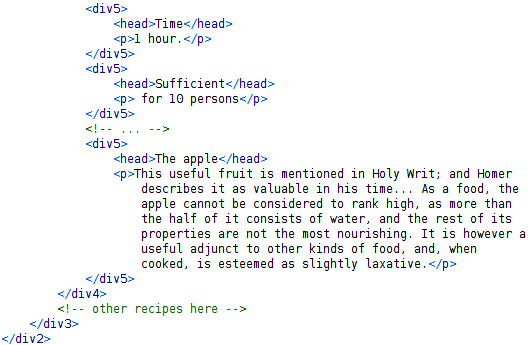
Wie in Abb. 1 zu sehen ist, wird die Struktur eines Kochbuches eins zu eins abgebildet. Die strukturelle Verschachtelungstiefe wird durch die nummerierten div-Elemente abgebildet, die Überschriften durch head-Elemente, die Paragraphen in p-Elementen und die Listen durch list- und item-Elemente.

Schema.org/Recipe
Schema.org/Recipe ist ein Vokabular, um Treffer von Suchmaschinen anzureichern. Die einzelnen Bereiche eines Rezeptes werden durch Microdata, RDFa oder JSON-LD kenntlich gemacht und können so von einer Suchmaschine ausgelesen werden. Abb. 2 zeigt einen Suchtreffer von Google zur Anfrage „Pfannekuchen“.

In Abb. 3 sind die hinterlegten Meta-Informationen auf der Webseite des Treffers in JSON-LD-Format dargestellt. Es wird unter anderem ersichtlich, dass das Vorschau-Bild in Google eine Vorschau des image-Attributes ist. Die Bewertung ist der Wert des aggregateRating.ratingValue-Attributes und der Vorschau-Text ist der Beginn des description-Attributes.
Die wesentlichen Bestandteile der Webseite mit dem eigentlichen Rezept sind hier zu sehen.

In kommerziellen Kochseiten
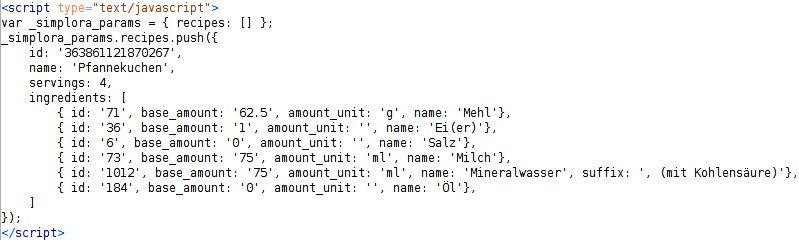
Wie im vorherigen Abschnitt gesehen, verwendet Chefkoch.de Schema.org/Recipe. Zusätzlich speichert Chefkoch.de jedes Rezept in einem JSON-Objekt, was am Beispiel des Pfannekuchen-Rezeptes in Abb. 4 zu sehen ist. Neben einer zusätzlichen ID (id) für das Rezept, werden die Einträge der Zutatenliste, welche bereits mit Schema.org/Recipe erfasst wurden, genauer aufgespalten. Jede Zutat hat eine eigene ID (id), Mengenangabe (base_amount) mit Mengeneinheit (amount_unit), sowie optional einen Kommentar (suffix).
Cooking.nytimes.com verwendet ebenfalls Schema.org/Recipe. Aus geht hervor, dass Cooking.nytimes.com zusätzlich ähnlich wie Chefkoch.de die Zutaten der Rezepte in einer Datenbank abspeichert, aufgespalten nach Name, Mengenangabe, Mengeneinheit, Kommentar und Anderes.